This post was originally published on the Open Government Products Substack. ICYMI: I’m publishing a book with No Starch Press! I wrote “From Day Zero to Zero Day” for newcomers looking to enter the rarefied world of vulnerability research.
The goal of good design and platform tools is to make resilience and security background information rather than foreground. In an ideal world, security is invisible - the developer isn’t even aware of security things happening in the background. Their workflows don’t feel more cumbersome.
Kelly Shortridge, Security Chaos Engineering
This is the first in a series of blogposts on first principles in building cybersecurity solutions at Open Government Products. Coming from an offensive security background, I’ve found that the most resilient solutions for cybersecurity problems address root causes directly, resulting in highly-scalable solutions that reduce overall work for the organisation.
However, many security programmes fall into a common trap where promising security solutions end up creating more and more work, eventually consuming a majority of resources and attention. Eventually, this detracts from solving more important security problems as teams are distracted with sending chasers, filing (digital) paperwork, and handling waiver requests.
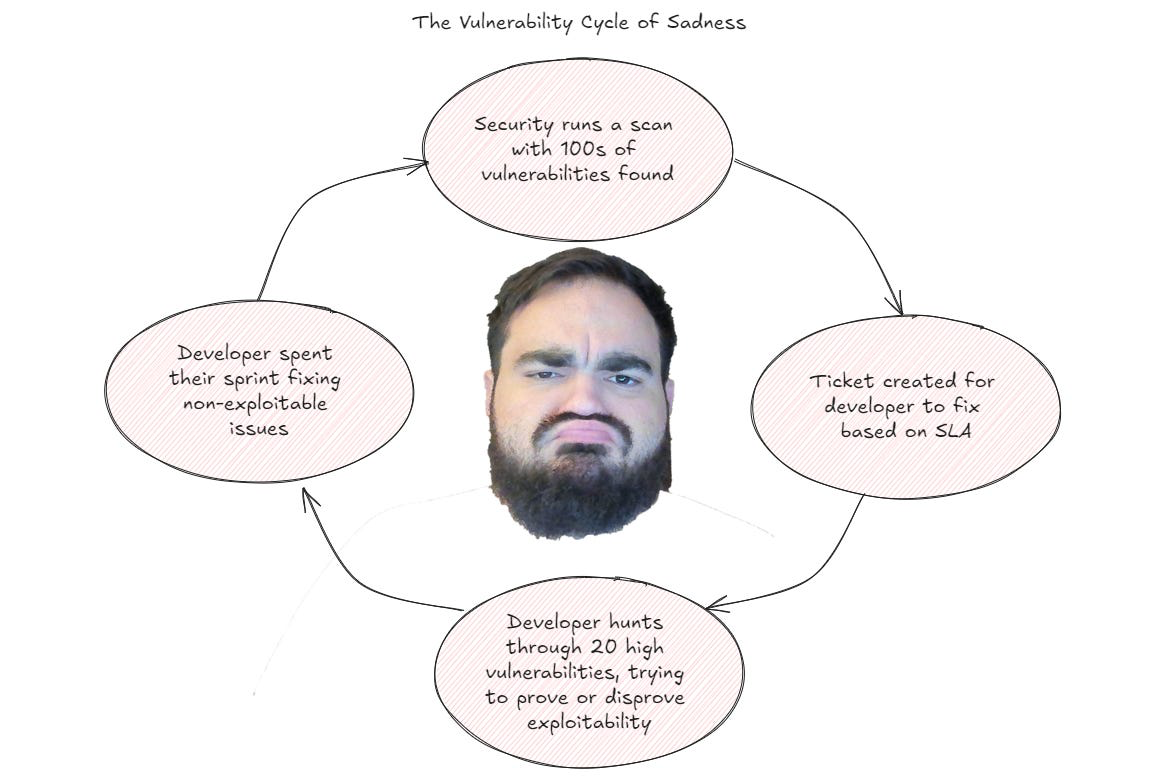
Let’s examine a not-so-fictional example:
*John Doe is an enterprising cybersecurity specialist in NotBeyondCorp. After a series of security incidents caused by simple injection vulnerabilities, he suggests purchasing a code-scanning solution to identify these vulnerabilities in the company’s codebases. In an initial trial, he assesses the findings and finds more than 50 exploitable vulnerabilities! Encouraged by the results, the company approves the solution and John is tasked with implementing it across the organisation.
Excited, John proceeds to roll out the solution. Despite a few hiccups (like breaking some CI/CD workflows), he completes the rollout. However, he quickly realises few of the developers are responding to the vulnerability findings. They’re too busy to triage them, or aren’t aware about the solution.
John tries a few quality-of-life improvements such as tuning the detection rules and sending automated reminders to developers. These improvements raise engagement slightly, but the effect is short-lived. In any case, it’s impossible to get a 100% true positive rate. The number of findings keep piling up and the time-to-remediate metrics are flashing red. John is discouraged: don’t developers know that vulnerabilities are important?
Out of ideas, John approaches management to push the big red button: mandate triage and remediation timelines for these findings. Convinced by John’s clear explanation of what could’ve gone wrong if the true positives had been exploited, management agrees. In order to enforce the mandate, John is given a couple of headcount to keep track of vulnerability findings.
With the number of unresolved vulnerability alerts in the thousands, John realises that he needs a proper workflow to manage them. His team creates a Jira workflow to automatically ping and remind developers (and also alert their managers if they don’t respond in time).
However, not everything can be resolved neatly - disputed findings, requests for waivers, and other queries start flowing in, requiring the team to respond to them manually. Sometimes, particularly belligerent teams escalate issues to management, requiring more meetings to deconflict. The team creates more Jira workflows for common issues like waiver requests, but at the end of the day, a human still needs to approve them.
John defends the mandate but is growing disenchanted. Most of the low-hanging fruit picked up in the early days of his initiative have been resolved, so the proportion of false positives is increasing as well. At this point, most of the man-hours poured into the initiative involve triaging false positives or dealing with bureaucratic infighting. He wants to invest more time in improving the solution or building his own in-house integrations, but there’s always another meeting…*
This is a common scenario that occurs in many security programmes. While the initial intent is good and the results appear promising in the beginning, the actual return on investment greatly diminishes over time, especially when considering the opportunity cost of maintaining a compliance apparatus.
This is the first cybersecurity antipattern: busywork generators.
What Creates Busywork Generators? 🔗
In order to avoid this antipattern, it’s important to understand why this antipattern occurs, and the biases that contribute to it occurring.
Shallow Cause and Effect 🔗
At its core, John’s initiative sought to address exploitable vulnerabilities. This is critical but easy to lose sight of. With this in mind, any time spent on non-exploitable vulnerabilities is effectively a waste of time and resources, detracting from this goal. James Berthoty addresses this succinctly in a blogpost and accompanying graphic:
In my career securing cloud native applications, I have never seen proof of an exploitable CVE from a container image the context of my SaaS application. That’s despite thousands of vulnerability scans, with millions of discovered vulnerabilities, and untold developer hours fixing the things. The unfortunate truth is that the staggering number of false positives have caused real harm to security’s legitimacy in their organizations.
Source: James Berthoty, Latio Pulse
The trouble with many “shift-left” busywork generators is that a lot of the cost is shifted to developers, which isn’t accurately captured when assessing the effectiveness of the programme. Often, the total cost of operations is much higher.
What partly motivates this is bias towards blaming human error - in this case, “exploitable vulnerabilities occur because a human introduced them to the codebase.” Thus, the human responsible should triage and fix the identified vulnerability. On the surface, this is indeed true. But a surface-level assessment does a disservice to the organisation. It’s important to stay curious and take the opportunity to practice the five whys:
- Why did the injection vulnerability occur? Because untrusted input was directly used to construct a database query.
- Why was untrusted input allowed into query logic? Because developers wrote raw SQL without using safe abstractions like parameterized queries.
- Why were developers able to use raw SQL in the codebase? Because the development environment didn’t restrict or control how database access was implemented.
- Why wasn’t access to unsafe APIs or patterns restricted? Because there were no architectural controls like secure-by-default libraries or frameworks that eliminate the use of unsafe patterns.
- Why wasn’t the system designed to enforce safe patterns and disallow unsafe ones? Because the application stack didn’t include guardrails that make the secure way the easy (or only) way, such as a security-hardened ORM, or frameworks that prohibit raw query construction.
With deeper analysis, you can identity many more potential solutions other than “yet another alert generator,” giving you more options than the lowest common denominator solution that doesn’t scale well.
Wrong Solution Prioritisation 🔗
To be clear, this doesn’t mean that an alert generator is the wrong solution - circumstances may be dictate starting with easier solutions first. There’s an entire field of security operations dedicated to detection and response (which will be discussed in a future post).
Gaining initial visibility into your vulnerability numbers is an important first step. However, in application security, you should prioritise your solutions according to how well they can address root causes. For this, I like to refer to Kelly Shortridge’s Ice Cream Cone Hierarchy of Security Solutions:
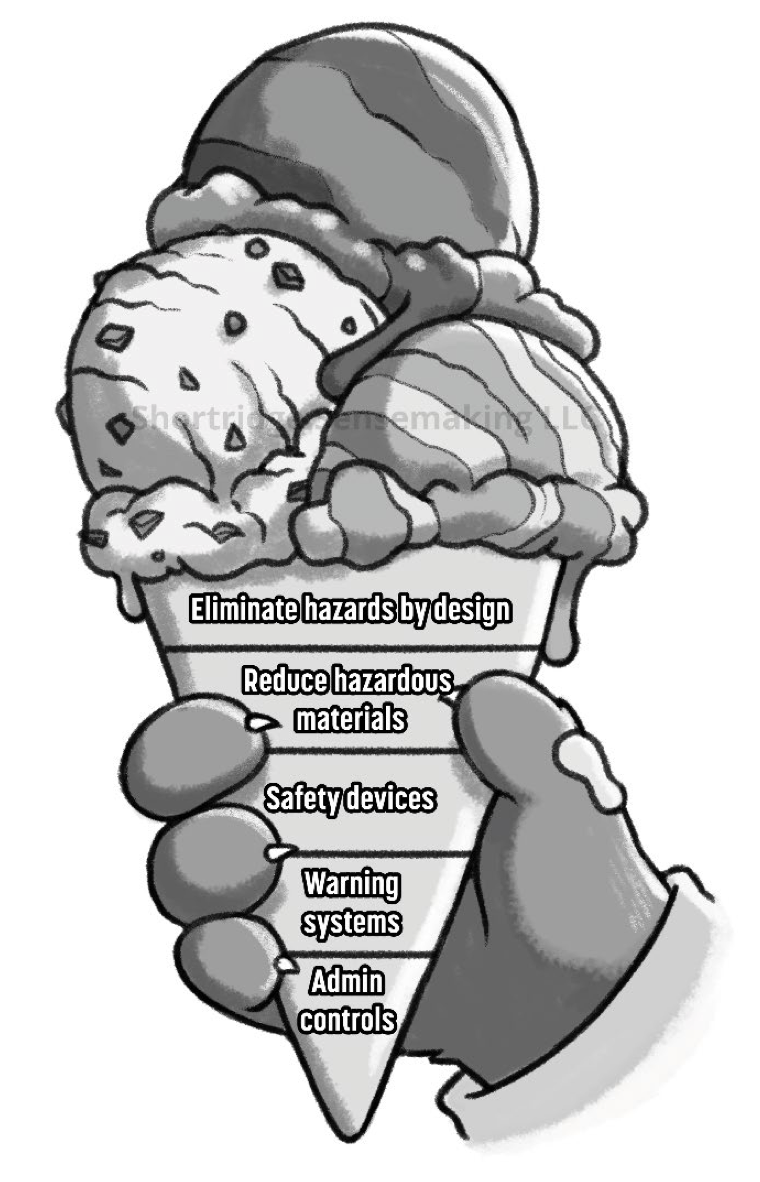
Source: Kelly Shortridge, Response to CISA Request for Information
While the framework is drawn from the well-established Hierarchy of Controls used in many industries, it’s unfortunately neglected in the cybersecurity domain. In short, the weaker solutions at the bottom of the ice cream cone rely more and more on human intervention to succeed, while the ones closer to the top eliminate hazards by design.
Any solution that relies on human intervention bakes in a margin of error - we’re only human, after all - that then requires additional interventions to address. Recall the Jira workflows, email chasers, and meetings John had to do just to ensure developers patched their bugs. This is where the busywork comes from, and why his solution was doomed to generate more and more of it. Worse, this means that the actual outcome of eliminating exploitable vulnerabilities can never reach 100% - there’ll always be one more untriaged or mistakenly-dismissed alert.
Lack of Mechanisms 🔗
At this point, you might have a common and very reasonable objection - not everyone has Google’s security team with the capability to build and roll out an entire web framework.
It would be nice if Google open-sourced their high-assurance web framework, but it might be overly-optimised for Google’s internal toolchains and patterns anyway. Some organisations may have highly heterogenous internal environments that preclude a singular framework.
This is a big contributing factor towards selecting a lowest-common-denominator solution like an alert generator. It’s within the zone of control of most security teams that lack org-wide mechanisms to effect change.
How do you avoid Busywork Generators? 🔗
Now that you understand what leads to Busywork Generators, let’s explore how to avoid these causes and explore alternatives. The key is starting from these first principles:
Getting Clean isn’t the same as Staying Clean 🔗
There’s a common approach in the DevSecOps space of “get clean, and stay clean.” “Get clean” refers to resolving all the outstanding findings, while “stay clean” refers to stopping new findings from occurring. The key principle here is that these are two separate tactics. More critically, “getting clean” is a temporary first step, while “staying clean” is the long term solution.
Think of it as bailing out water from a sinking ship. You could theoretically add more people to bail water, but at some point you need to patch the hole that’s getting bigger. A common mistake is to believe that you need to get completely clean before staying clean. This is an impossible task; there will always be new issues pouring in.
Instead, get clean enough where you’ve addressed the truly-exploitable high and critical issues, then move onto staying clean. John’s mistake was to hyper-focus on getting clean and not setting a point in time to start investing in staying clean.
There are multiple ways to set a reasonable “clean enough” point - exploitability or reachability, severity, KEV/EPSS for CVEs. Just set that point and commit to it. At OGP, we leveraged Dependabot auto-triage rules, wrote our own CodeQL ruleset, and invested a couple cycles on tackling the (prioritised) vulnerability backlog, before setting alerts for high-severity vulnerabilities. This gave us space to explore “stay clean” solutions while maintaining a reasonable baseline for important vulnerabilities.
A truly scalable solution to code vulnerabilities would look more like Google’s Blueprint for a High-Assurance Web Framework, in which Google’s security engineering team built-in multiple security controls. Their sharing sounds a lot like Shortridge’s quote at the start of this post:
It is worth emphasizing: Everything in this list is maintained by the security team. With our high-assurance web frameworks, application owners don’t need to be aware of any of these features - they all are enabled and work out of the box.
At OGP, we built a Starter Kit in which the security engineering team has built-in security components (Starter Kitty) to address some common repeated findings. While they didn’t work perfectly in our first attempts, we gradually hardened them over time with successive pentests across multiple products, ensuring that lessons learnt by one product team were encoded and transmitted to all other products going forward, allowing us to demonstrably eliminate a class of web vulnerabilities.
Good Intentions Don’t Work, Mechanisms Do 🔗
Any solution that relies on human intervention comes with a built-in failure rate. While developer training is important, it’s not foolproof - or an attacker might discover a novel attack vector. Understanding this principle helps you move away from alert generators or NagOps and look towards building real mechanisms.
Even if you lack existing mechanisms, part of the evolution from compliance to security engineering involves strong cross-disciplinary work - in particular, partnering with tooling, platform, devops and other engineering teams that possess high-leverage mechanisms. Security operating in a silo as blocker-in-chief is the easiest and worst mode of operation.
At OGP, the security engineering team didn’t build Starter Kit - the tooling team did. By working with them to introduce Starter Kitty components into Starter Kit, we also addressed significant developer experience and usability issues that engineers were more attuned to (observe this thread), improving our final implementation.
Recall how John initially broke developers’ CI/CD pipelines in his rollout. Security Engineering may sometimes lack the context of other engineering teams which is why close collaboration is important to avoid the “big red button”. Mandates are a mechanism as well, but they’re certainly not the most effective one.
In short, lacking the right mechanisms isn’t an excuse for using the wrong solution - build or find those mechanisms. I’ll discuss this more in a second blogpost on building effective mechanisms.
Case Study: tj-actions Supply Chain Attack 🔗
Let’s walk through how we can apply these principles using the tj-actions supply chain attack as a case study. With some ChatGPT assistance (with guidance to avoid alert generators), you can quickly map out the 5 whys:
- Why were our repos impacted by the tj-actions compromise? Because developers used a third-party GitHub Action that was compromised and automatically pulled in its latest version via a mutable tag (@v35, @v1).
- Why did our workflows auto-update to the malicious version? Because GitHub Actions uses mutable tags by default, and we allowed unpinned versions in production workflows. There was no enforcement preventing it.
- Why didn’t we prevent unpinned third-party actions from running? Because we didn’t treat GitHub Actions as production dependencies. Our security posture treats app dependencies (e.g., npm, pip) as immutable and scanned—but CI/CD dependencies are completely trusted and unaudited.
- Why were GitHub Actions treated differently from app dependencies? Because we lacked a framework or tooling that let us manage GitHub Actions like code dependencies. No lockfiles, no vetting process, no repo-to-action trust model - just plug-and-play.
- Why don’t we have that framework? Because GitHub doesn’t offer it out-of-the-box, and there’s no first-party support for things like lockfiles, central approval workflows, or dependency proxies for actions. We’ve accepted that risk as normal instead of solving it.
From here, you can generate a few possible solutions:
- Detect and alert on non-hash-pinned GitHub Actions.
- Scan, detect, and alert on malicious GitHub Actions at runtime or statically.
- Enforce hash-pinned GitHub Actions using a GitHub Policy.
- Only allow approved, whitelisted GitHub Actions.
I’m sure you can think of a few more yourself - and vendors are usually more than happy to suggest a few of their own products in response to such events. But which solutions address the root causes, and where would they fall in the Ice Cream Cone Hierarchy of Security Solutions?
Busywork Generator Solution
A negative Busywork Generator outcome would be perhaps the “detect and alert” solutions, or even the whitelist; this puts more humans in the loop through warning systems and admin controls.
Root Cause Solution
However, in this case GitHub does offer a clear mechanism for Enterprise-wide policies on GitHub Actions. This is necessarily a breaking change because developers can no longer use untrusted actions. As the Google blogpost on the High-Assurance Web Framework shares:
Some of these features do constrain the code that application owners write (e.g. they’ll block writing code such as
document.body.innerHTML = "foo") but this is a purposeful part of our “Safe Coding” approach to security…
“Make the secure way the easy (or only) way” is possible but the security team needs to own the rollout fully to reduce unexpected breakages and ensure maintainability.
What We Did
There’s just one catch to the GitHub policy feature: GitHub only allows restricting actions to internal actions, those owned by verified marketplace creators, official GitHub actions, and whitelisted ones. However, this could address the actual root cause of forcing hash-pinned dependencies.
Fortunately, we were able to create a workaround for hash-pinned actions using patterns in the whitelist. While imperfect, this sufficed until GitHub actually adds hash-pinned actions as an option in the policy. We also decided to allow marketplace verified creators and official GitHub actions to reduce the number of failing actions the moment we implemented the policy, reducing developer friction.
More importantly, we worked with our engineers by building a custom GitHub app that identified and informed developers of all untrusted actions that would fail once the policy was implemented - you can see an example for FormSG here. This reduced the amount of unpleasant surprises when we flipped the switch.
Finally, we created monitors for GitHub Actions breakage metrics and logs to watch alert us if the new policy caused spikes in failures, ensuring we could rollback in a timely manner if needed.
You may come to a different solution depending on your organisation’s context, but you can see how this approach meets the two principles:
- Getting Clean isn’t the same as Staying Clean: We invested some time to identify untrusted actions and alert developers about them, but this paved the way for an automatically-enforced GitHub Policy that prevented more untrusted actions. We didn’t stagnate at the detect-and-alert stage.
- Good Intentions Don’t Work, Mechanisms Do: Using hash-pinned or trusted actions can be cumbersome. It introduces an element of surprise when an unknowing developer using an untrusted action that fails. It’s reasonable to assume that nagging developers to use trusted/hash-pinned actions won’t work. Instead, we made trusted actions the only path, but we made it as easy as possible with our prep work and friendlier policy choices.
Conclusion 🔗
In this blogpost, I’ve explained down some first principles in cybersecurity solution design that hopefully illustrate what distinguishes a good solution from a bad one. Your security programme may not always have the capability or mechanisms at this moment, but it’s important to develop good taste:
“Nobody tells this to people who are beginners, I wish someone told me. All of us who do creative work, we get into it because we have good taste. But there is this gap. For the first couple years you make stuff, it’s just not that good. … Your taste is why your work disappoints you. … It’s gonna take awhile. It’s normal to take awhile. You’ve just gotta fight your way through.”
Ira Glass
In my next article, I’ll discuss some lessons we learnt at OGP on building effective mechanisms to support strong security solutions.